BLUE: Toward Better Language Use in Efficient
Vision-Language-Action Models for Autonomous Driving
George Ling,
Lijin Yang,
Hao Yang,
Zhongzhan Huang*
Bosch Research
* Corresponding author
Code, data, logs, and checkpoints will be fully released.
76.2%
Bench2Drive SR
36
Longest6 v2 DS
2.54x
Inference speedup
0.11M
Trainable Param.
Closed-loop Demonstrations
Example closed-loop runs in CARLA: BLUE demonstrations and comparisons against the SimLingo backbone.
Ours Demonstrations
Representative closed-loop runs completed by BLUE.
Sudden door opening on a two-way road
Construction obstacle on a two-way road
Pedestrian crossing outside a crosswalk
Backbone vs. Ours
BLUE improves driving success rate while reducing inference latency.
Turning at a blocked intersection
Left turn into congested unsignalized junction
Abstract
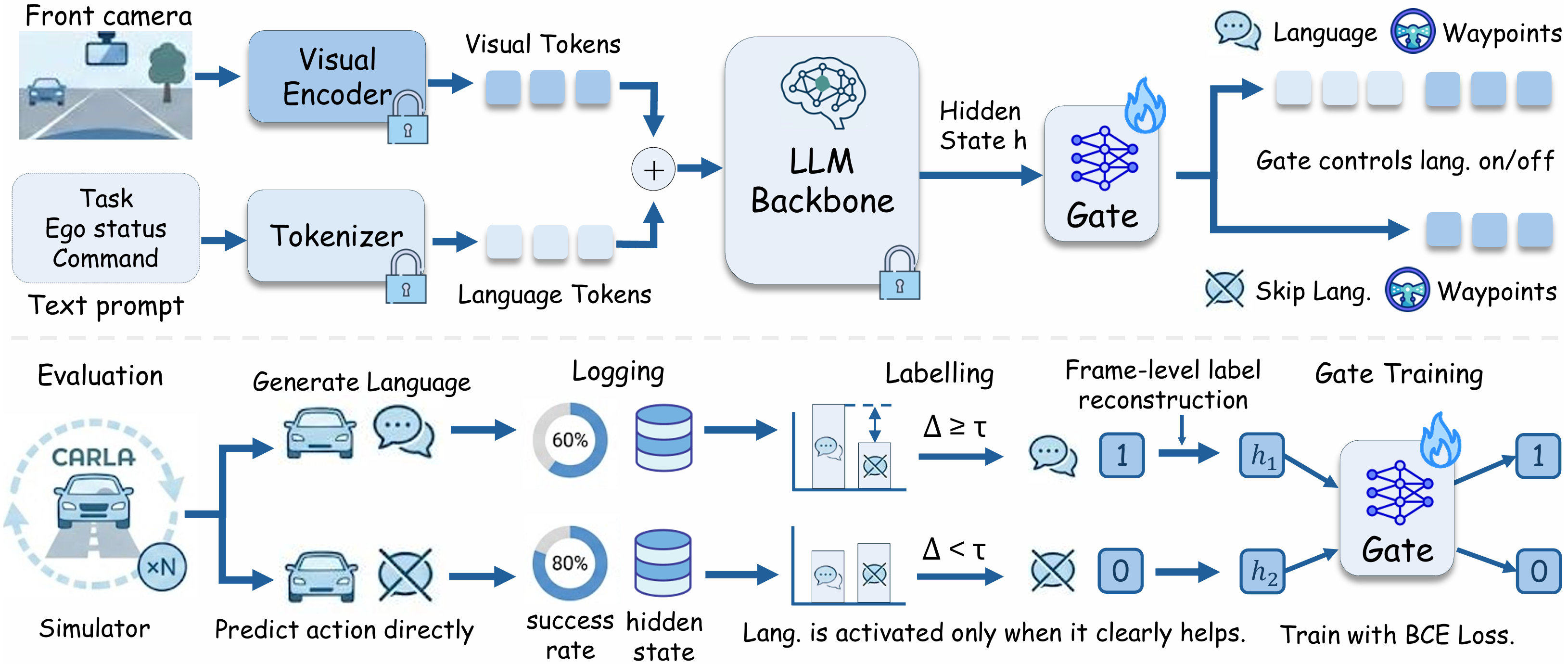
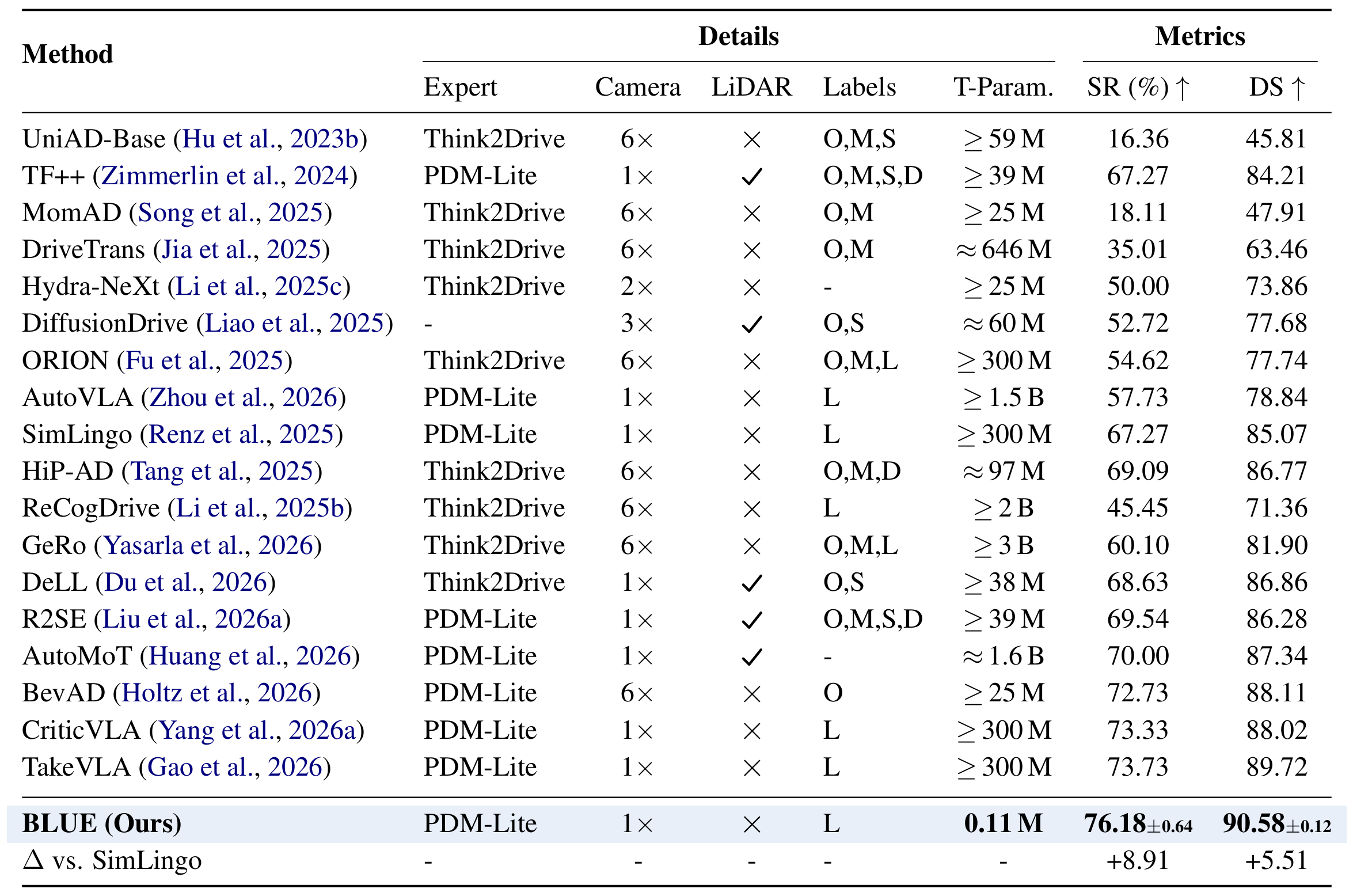
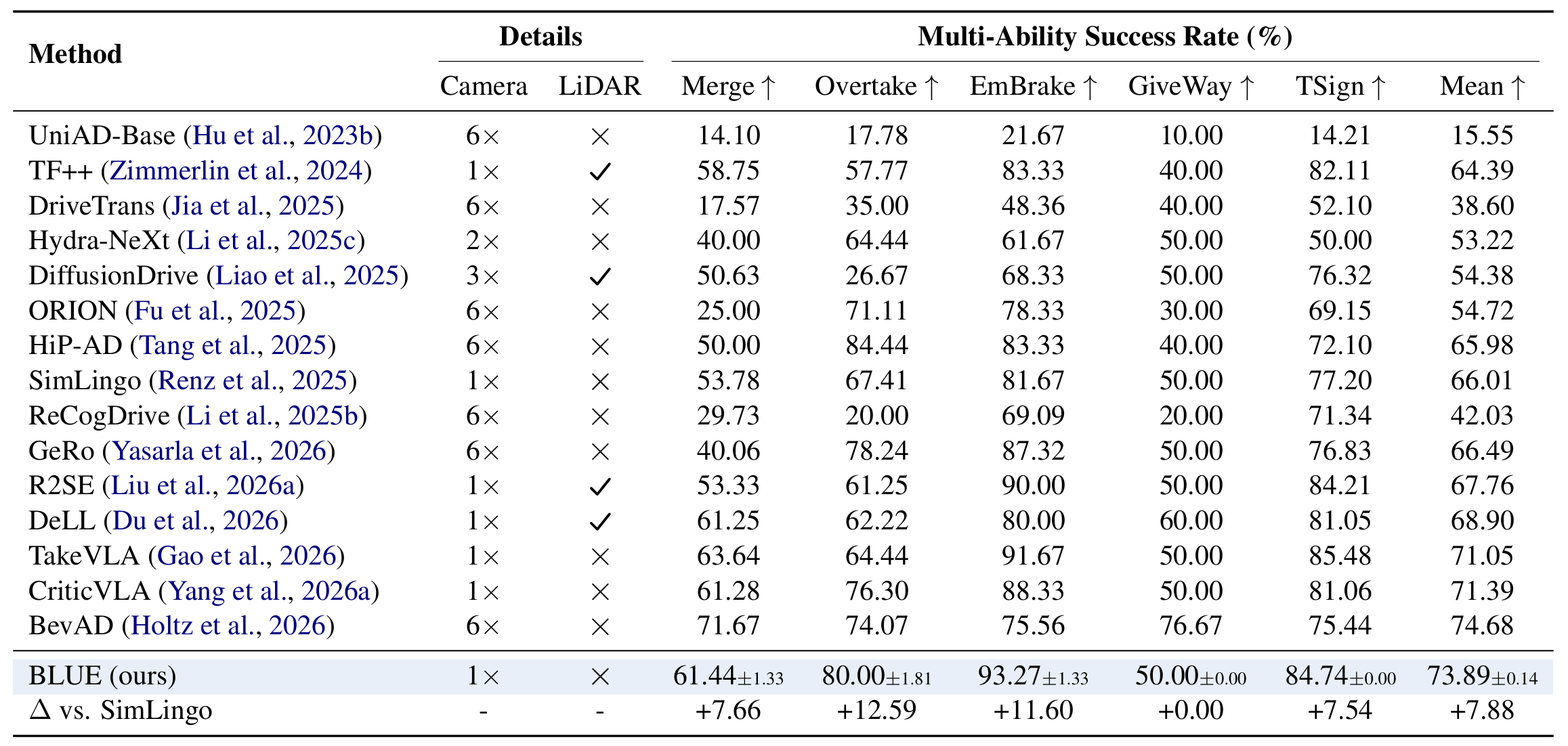
We present BLUE, a minimal method for better language use in vision-language-action (VLA) models for autonomous driving (AD). Through extensive analysis, we reveal that language matters on only a small fraction of routes, but on those routes it can greatly improve or degrade performance. Generating language at every frame is therefore inefficient, since most computation is spent on frames that do not benefit from language. We further show that pretrained VLA hidden states potentially already encode whether language will benefit a given frame, even though scene complexity and kinematic features alone struggle to predict this. Based on this finding, BLUE trains a lightweight gate on frozen VLA hidden states to decide per frame whether to activate language generation or predict actions directly, without modifying the backbone or requiring additional human annotation. With just a 0.11M-parameter gate, BLUE sets a new state of the art on both benchmarks, achieving 76.2% success rate on Bench2Drive and 36 driving score on Longest6 v2, while delivering 2.54x inference speedup and 8.9% success rate improvement over the backbone. BLUE provides a practical path toward efficient language-augmented AD, showing that VLA models can retain the benefits of language at a fraction of the cost.